
The 29-minute Breakout: Why monthly vulnerability scanning no longer works
TLDR: We attended Cyber Security 2026: Kritisk infrastruktur in Stockholm, and the reality check was simple: “breakout time” has hit a record low of 29 …

Rickard Carlsson

There is a common belief that when it comes to uncovering bugs in the DevSecOps cycle, catching things early on is often better. While this approach certainly works well for Software Composition Analysis (SCA) and Static Application Security Testing (SAST), it doesn’t really apply to Dynamic Application Security Testing (DAST) in modern environments.
I’ll explain why catching things early on is a naive approach and requires a much more granular analysis, especially in times when cyber needs to be balanced with the available resources.
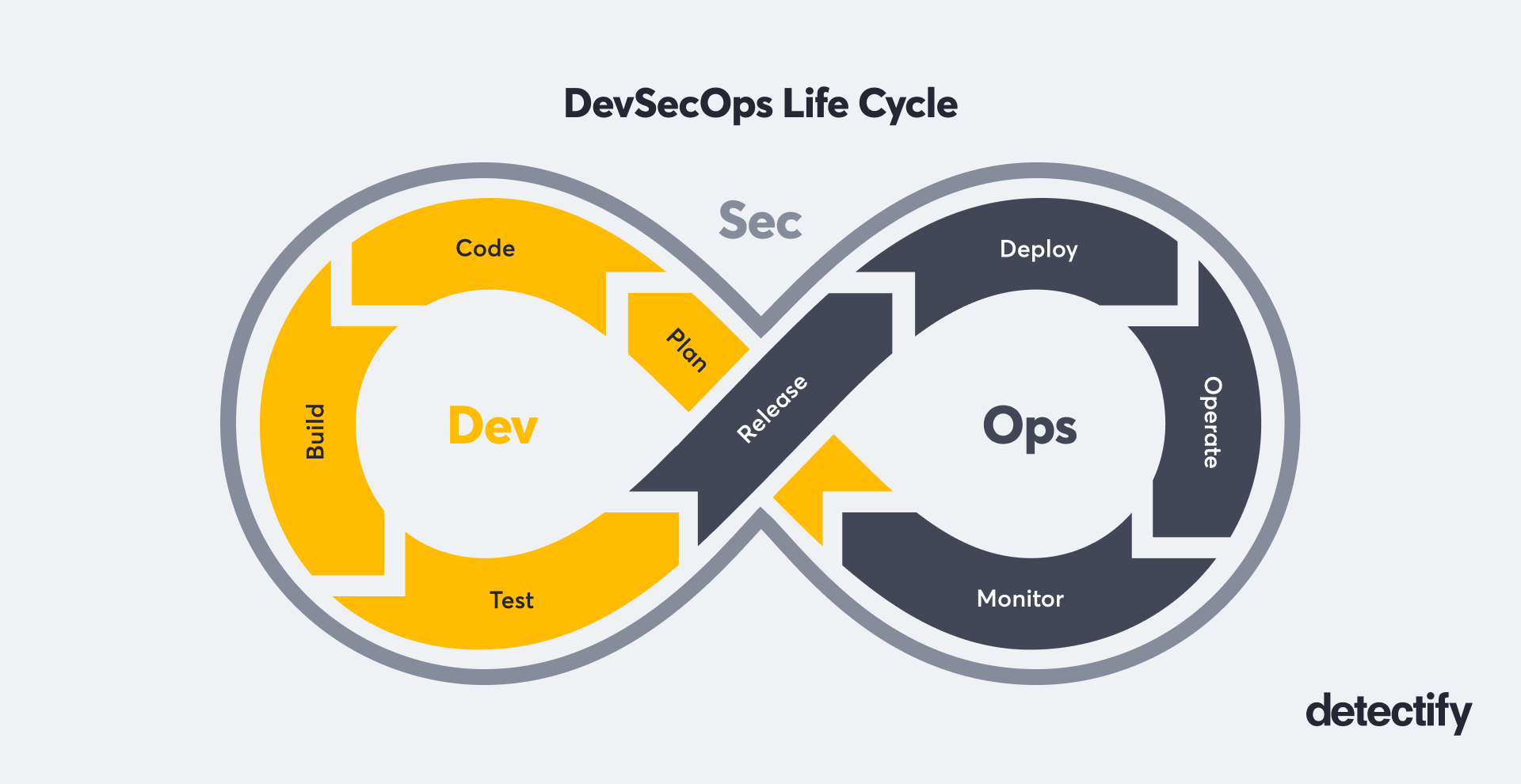
If we take a step back and examine what AppSec teams aim to do during the DevSecOps cycle, their overall objective should be to minimize risk for the organization. However, cyber teams need to deliver with limited resources in terms of both people and cost.
When comparing elements of risk, resources, and technical complexity, the question of testing in staging vs. production environments can get quite complex.
Although there are various ways to think about risk, the base for most frameworks include factors like impact and likelihood. Vulnerabilities are typically rated by severity (for example, CVSS), with scoring being framed around impact and likelihood. However, this type of scoring doesn’t offer a complete picture of a vulnerability’s true impact (the math behind CVSS is something I talked about here). This incomplete view doesn’t take the entire context into account – in other words, your specific business condition or the potential attack path. Risk to your organization is entirely dependent upon your organization’s business conditions, not the CVSS score.
What if we instead break risk down by different factors? These could include:
These elements can also be seen as drivers of impact and likelihood, but are easier to relate to in terms of the processes attached to them. For example, data at risk is a fixed variable and cannot be adjusted – instead, it sets the context of the exposure time and severity.
When looking at many security processes, there’s a very strong focus on reducing the number of high severity vulnerabilities that are detected in production. It is, after all, a logical approach to aim to catch vulnerabilities earlier in the development process in order to never introduce these vulnerabilities into production. However, this method is mainly relevant for vulnerabilities that have been introduced by developers as coding mistakes (e.g. good for SAST and SCA).
There are multiple issues that can’t be prevented from reaching production, such as:
Because of their emerging nature, it’s simply not possible to prevent these types of issues from making their way into a production environment. What would then trigger testing of the staging environment? It becomes more problematic, as the application that’s now vulnerable might not be actively maintained.
What’s more, there are various issues that can’t be detected in staging:
And while it may sound obvious, it needs to be said: Staging is never the same as production. Staging environments typically run with different configurations than production environments. For example, one may have CORS set, while the other doesn’t, or features may be available on one, but not the other. In reality, the entire attack surface can actually be entirely different on your staging and production environments.
With this in mind, it’s virtually impossible to get a state in which zero vulnerabilities are identified in production environments. In addition, a large share of applications that are exposed are not being actively developed (various sources claim up to 80% or more are not actively maintained).
Perhaps your team may still be convinced that running dynamic testing in staging environments (so-called ‘shifting left’) is a sufficient way to get a complete view of your organization’s attack surface. If so, ask yourself:
Put simply, my recommendation to AppSec teams is to only run dynamic testing in production. Instead of pushing all testing to staging, there’s a good chance that your team can benefit from placing more of a focus on your resolution time.
If this is a topic that your team is beginning to work on, you can first examine how you’re currently approaching your resolution time — for example, are you measuring it in hours, days, or weeks? The best in class is the mean time from identification to resolution measured in hours. What’s more, creating an actionable plan in place to minimize your resolution time can serve as an invaluable resource for your team.
In modern dev processes, production is what truly matters. To defend your organization, you must have a plan for catching vulnerabilities that make it into production and to quickly remediate those that represent the most risk. Continuously testing the entire attack surface with real payloads that identify active vulnerabilities and highlight those that represent the most risk has to be part of the equation. That’s where Detectify comes in.
TLDR: We attended Cyber Security 2026: Kritisk infrastruktur in Stockholm, and the reality check was simple: “breakout time” has hit a record low of 29 …

Detectify vs Acunetix is a common comparison for AppSec teams evaluating Dynamic Application Security Testing (DAST) tools. This article provides a direct comparison between Detectify …

