Detectify Crowdsource hacker Akhil George, aka streaak, is a full-time student who chases bug bounties during his free time. His hacking interests started with CTF competitions and eventually shifted to bug bounties, gaining him recognition abroad including this report from NBC. Our Crowdsource guest blogs give readers an inside look into the mind of an ethical hacker, this month’s contribution goes on to discuss the recon techniques streaak used in 2019.
Foreword from streaak: This is purely my attempts at recon. It’s in no way complete and it’s something I have been working on for sometime now. If there’s any improvement/suggestion to be made in my recon methodology, let me know in the comments section or directly. Let’s go!
What is recon?
According to me, recon consists of the methods followed to widen the attack surface of a target or to fingerprint the acquired targets and much more. We (ethical hackers) can use different methods to cover as wide area as possible so as to leverage this information for better understanding of the target.
In this post I will talk about my workflow in these steps:
- Subdomain recon
- Passive endpoint gathering
- Subdomain takeovers
- Directory brute-forcing
- Visual recon
- Javascript recon
- Sensitive Data Exposure: Firebase and Slack webhook tokens
- Managing data and failed attempts
Subdomain recon
This is the initial part of my recon process. This is one of the main steps as it gives us an idea of the 3rd party services used by the company, their coverage and maybe stumble across some interesting endpoints from where we can further perform our recon. My goal here is to find as many valid subdomains as possible and I try to combine as many useful tools as possible to widen the attack surface.
Some of the tools I use:
- Subfinder (Passive subdomain enumeration)
- Amass (Passive and active subdomain enumeration)
- Massdns (Subdomain bruteforce using wordlist)
- Dnsgen (Alterations)
There’s also a tool called findomain which I haven’t had a chance to look at but heard great things about.
The flow goes something like this:
- Run subfinder with API keys to external services, such as VirusTotal, Passivetotal and SecurityTrails among others. This helps us cover a wide range of passive data sources.
- Gather subdomains from data sources not covered in Subfinder
- Run Amass for active and passive gathering of data
- Parse locally downloaded FDNS (Forward DNS) dataset to gather subdomains
- Run massdns with wordlists from commonspeak
- Gather all the domains from above, run alterations
- Resolve them and continue with the endpoint gathering.
One of the restrictions I came across in this process was the exclusion of wildcard domains in the recon process. 003random has a check for wildcard domains which I use as of now.
Remediation tip: Companies can prevent unnecessary data exposure here by having an auth for internal domains and admin panels.
Gathering endpoints passively
I usually gather endpoints passively using data sources as they have endpoints which sometimes cannot be found by brute-forcing.
Data sources I use for gathering endpoints:
Each of these services does passive scanning of data and hold datasets of URLs present, making it a good idea to go through each of them.
Note that this technique isn’t perfect as it doesn’t cover the complete attack surface and sometimes we end up having no output at all. I would recommend spidering and directory brute-forcing to cover as much as possible.
JavaScript recon
The way I proceed with JavaScript recon is by first gathering the JavaScript files. For this I use the tool called subjs written by Corben.
Once the files have been gathered, I run a tool called meg which was written by tomnomnom. What meg does is it gathers the content of the JavaScript files and saves it onto a directory which can then be used for further processing.
Potential further steps:
- Use linkfinder to gather links present in the JavaScript files (API endpoints, etc).
- Use gf to grep for sensitive information present in the JavaScript files (API tokens, technologies used, etc).
- Grep for comments in the js files.
Looking at the js files gathered, we can also figure out the technologies used by the company on the present domains. This helps us provide a better understanding of the technologies that the domains are built on.
Subdomain takeovers
Subdomain takeovers are the bug class which allows an attacker to takeover a subdomain due to an unused DNS record pointing to a domain belonging to the company. This whole year I’ve been entirely focused on subdomain takeovers limited to services on Azure (Cloudapp, Azurewebsites etc) and AWS Elastic Beanstalk. The way these services can be potentially identified as vulnerable is if they return a status of NXDOMAIN (Non-Existent Domain), while the CNAME records are being pointed to that respective service.
However there are some cases where even the ones with NXDOMAINs aren’t vulnerable. One of such cases of trafficmanager.net is mentioned here. Patrik has an amazing blog related to takeovers and I’d recommend checking that out. In the case of Elastic Beanstalk, what I’ve noticed is that the CNAME of the format “appname.region.elasticbeanstalk.com” can be taken over while CNAME of the format “appname.elasticbeanstalk.com” can’t be taken over.
Flow:
- Gather DNS records of all the gathered domains which have the NXDOMAIN status.
- Grep for the CNAMEs which can be potentially vulnerable.
- Takeover the subdomain
- Profit???
Sensitive data exposure
A lot of sensitive data can be exposed publicly intentionally (code commits) or unintentionally (password dumps). At this phase, I am focused on 2 types of tokens that can be leaked and how they can be leveraged: slack webhook tokens and Firebase API tokens.
Slack webhook tokens
Unfortunately it’s common for Slack webhook tokens to be accidentally made public and we can use this to post messages to the slack channel they’re linking to.
This trick has been published by Intigriti but I wanted to mention it here with some additional information. This trick was originally found by JR0CH17 and I was able to test it against multiple bug bounty programs.
Viewing the source code of the no-SSO version of a non-enterprise Slack instance belonging to a company can reveal the team_id of the Slack instance (This is perfectly normal as team_id is supposed to be public). Since Slack webhook tokens contain the team_id, we can grep for them on different search engines and also on GitHub and check for their validity.
Slack webhook tokens are in the format: https://hooks.slack.com/services/T00000000/B00000000/XXXXXXXXXXXXXXXXXXXXXXXX
Where T00000000 is the team_id.
These can be verified if it works by running the following command:
curl -s -X POST -H "Content-type: application/json" -d '{"text":"streaak"}' WEBHOOK_URL
Response:
ok
An example:
Let’s consider the source code for https://digitalocean.slack.com
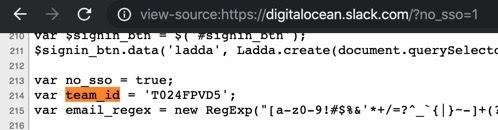
Here we go ahead and search for the above team_id on https://gist.github.com
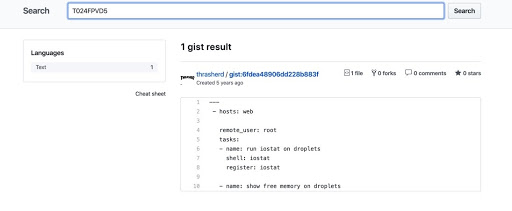
As you can see, we get one result. From here we can actually proceed to see if the key is valid.
However, the token above is invalidated.
Firebase API tokens
I’ve been coming across Firebase API tokens for quite some time now. It is usually intentionally left public and doesn’t have an impact on its own. However, there is a particular implementation which could have high impact to the company and this is when we can actually create accounts to restricted logins, which could give us access to confidential information.
This was first found by EdOverflow and he helped me escalate it. I came across firebase keys where the firebase app had a login panel which was limited to admins only. From the documentation, there is an endpoint that can help us sign up and create an account for the admin panel, which lets us login to the Firebase instance.
The request:
curl 'https://identitytoolkit.googleapis.com/v1/accounts:signUp?key=[API_KEY]'
-H 'Content-Type: application/json'
--data-binary '{"email":"[user@example.com]","password":"[PASSWORD]","returnSecureToken":true}'
Response:
{
"kind": "identitytoolkit#SignupNewUserResponse",
"idToken": "tokenhere",
"email": "emailhere",
"refreshToken": "refreshtokenhere",
"expiresIn": "3600",
"localId": "value"
}
meg+gf
Meg is a tool used for gathering responses for a path or a set of path for a list of domains. Gf is a tool used to grep for keywords in a huge dataset quickly.
I’ve been used to using meg a lot for gathering the html and was using grep to filter out the key terms which was a slow process. I came across gf in STÖK’s video where he interviews Tomnomnom. I’ve been using it since and it’s been one of my go-to tool for recon.
Some of the above mentioned techniques use meg and gf as well. For example, I use meg and then gf to look for slack webhook tokens and also firebase api tokens using the right regex.
Some cases where I applied this:
- When the recent Pulse Secure SSL VPN exploits released, I, with the help of Alyssa, used my already gathered meg data with the pattern
dana-na to grep for HTML containing that term. This led me to a lot of those instances.
- Similar to the above exploit, I followed a similar approach for Fortinet where I used the pattern
Server: xxxxxxxx-xxxxx which was one of the headers returned by the server.
- I created a similar one for the vBulletin RCE with just the term vBulletin and I was able to find one server vulnerable to the RCE.
Tip: I’d recommend creating more gf profiles depending on your case scenario to utilise it to the maximum.
Directory and endpoint brute-forcing
This is the process where one can find directories and endpoints by brute-forcing it against a wordlist. I have my own curated wordlist for this approach. The main limitation that I came across with this approach was not having the ability to give a file containing hosts as input. Of course, dirsearch allowed this but it was slow even with a good amount of concurrency. So I decided to use the combination of parallel with gobuster. Since gobuster was written in Go, it was fast and I could take input from a file using parallel. I run it with my custom wordlist.
cat urls.txt | parallel -j 5 --bar --shuf gobuster dir -u {} -t 50 -w wordlist.txt -l -e -r -k -q | tee out.txt
Parallel creates 5 jobs, that is, will run on 5 domains at once in this particular case and gobuster will do the directory bruteforce with 50 threads each domain. I’d recommend being careful with this approach as it might quickly drain system resources and also you might get abuse notice from your cloud provider or potentially get banned by the program.
Visual recon aka screenshots
I perform screenshots on the gathered subdomains as I can quickly filter out the interesting subdomains just by looking at them. Most of my recon is done on my VPS but I run screenshots on my local ubuntu install so as to view it at ease. The tool I use is gowitness.
Flow:
- Use scp to copy the url list from VPS to local system.
- Use gowitness to take the screenshots.
- Generate the gowitness DB.
Other tools you can use are Eyewitness or httpscreenshot.
Managing data
Managing the data can be a difficult task depending on how you do it. I use text files instead of creating a DB as I prefer it that way, Each domain has a folder and output of each tool will create a text file. I keep the text files so that I might use it for particular tasks as I come across it.
I do a check for the existence of the file previously for the tools that return the same output for every run, in case I were to run the same scan every time. This is not the best procedure but it works for me.
Other additional stuff
- Grabbing titles of each web page.
- Grabbing domains which return SERVFAIL response to check for NS records based takeovers.
- Grabbing all the DNS records to look for particular CNAMEs or such.
Failed attempts
Gathering the ASNs an organisation is under, to get the IP ranges.
I followed this flow:
-
- Gather the ORG name from the SSL cert
- Use the IP output from aquatone and grep each IP with the organisation name using whois.cymru.com to get the ASN. This is done to avoid ASNs belonging to cloud providers.
- Then used hackertarget’s API to gather IP ranges for the gathered ASNs
The limitations on hackertarget’s API and the inefficient method of gathering ASNs didn’t work out for me and I ended up abandoning the script.
Using shodan CLI for details on each host.
Here I tried to use the IP addresses gathered from aquatone to feed it into shodan CLI using the following: shodan host $IP | tee -a shodan.txt
This idea was abandoned because of limited credits on shodan and because the entire process was slow and would take forever if you had gathered a lot of IPs.
Conclusion
So this was my approach for recon throughout the year of 2019 and everyone mentioned above has directly or indirectly helped me in making it possible. Hope you’ve learnt something from my article.
More from streaak;
Twitter: https://twitter.com/streaak
Blog: http://streaak.co/



